
When to Use Which Vector Database for the RAG?
The core difference between Pinecone, Weaviate, ChromaDB, Milvus, Qdrant, and Postgres/pgvector for storing embeddings for RAG

In the previous article on Harnessing AI Models, I listed some databases that can be used for the RAG.
Harnessing AI Models

LinkedIn and X are full of posts about harnessing, and at any AI team meeting or gathering, you will hear things like:
My best friend, Manal Samy, commented that she needs more context about them: What is the difference between them? How to use them with a tutorial?
I already wrote three articles about RAG before. The first link below is for the step-by-step tutorial. I used PostgreSQL because that is what I usually use in my courses and at work. The other two links are for further reference.
Part 2-RAG in Real Life: Embeddings, Vector DBs, and a Colab Notebook Skeleton You Can Run Today

In Part 1, we treated large language models (LLMs) as smart text predictors with limited working memory.
Part 2-RAG in Real Life: Embeddings, Vector DBs, and a Colab Notebook Skeleton You Can Run Today
In Part 1, we treated large language models (LLMs) as smart text predictors with limited working memory.
The core difference is this: Pinecone, Weaviate, ChromaDB, Milvus, Qdrant, and Postgres/pgvector all store embeddings for RAG, but they differ in scalability, performance, cost, and operational complexity.
Below is a structured, citation‑grounded comparison based on recent evaluations of vector databases.
[data-dynamics.io]
[tensorblue.com]
What is each system in the RAG stack?
Pinecone: Fully managed, serverless vector database focused on simplicity and reliability.
Weaviate: Open‑source vector DB with strong hybrid search (vector + keyword) and multimodal support.
ChromaDB: Lightweight, developer‑friendly, open‑source vector store often used for local RAG.
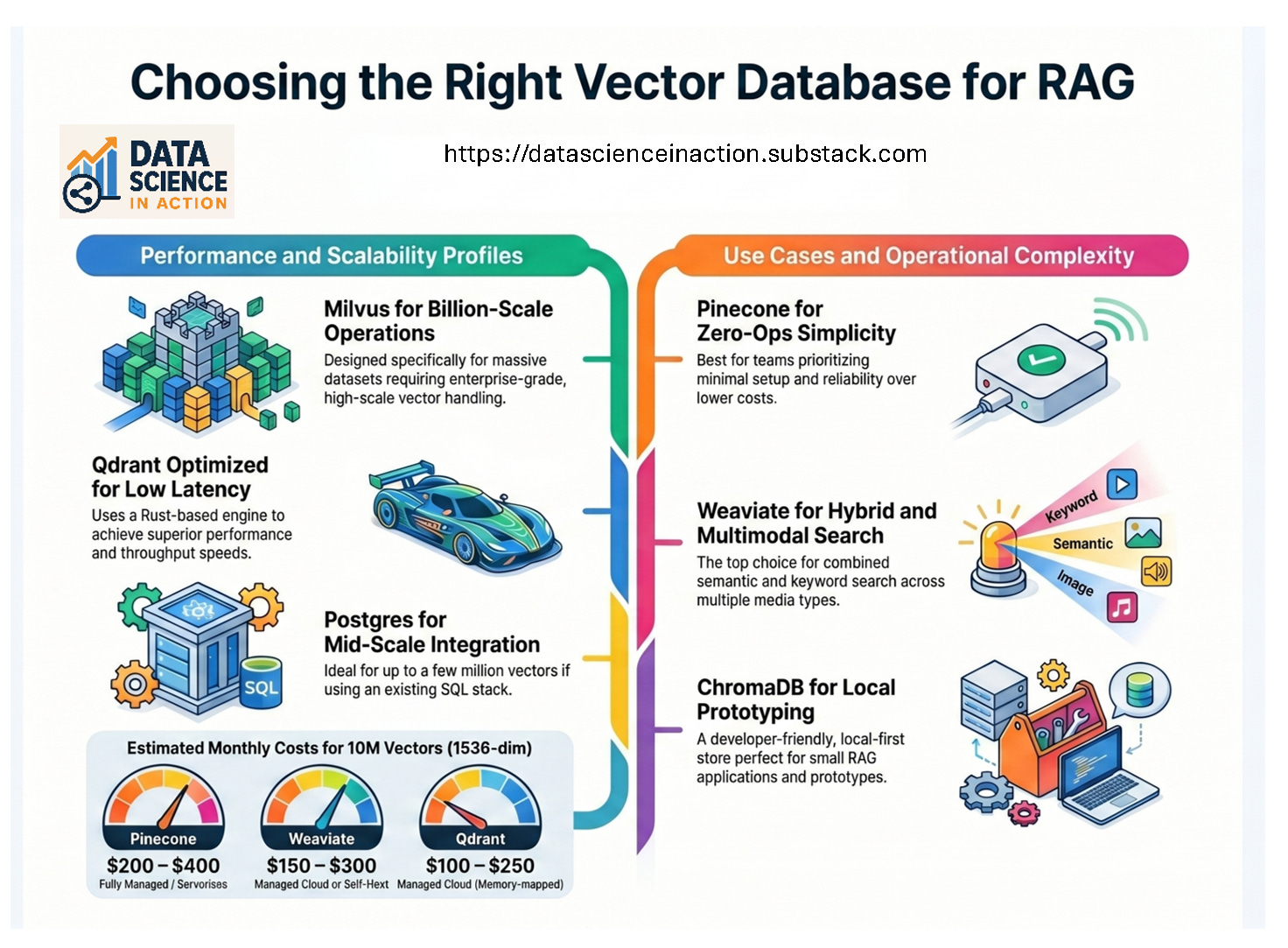
Milvus: Enterprise‑grade, high‑scale vector database designed for billions of vectors.
Qdrant: High‑performance, Rust‑based vector DB optimized for low latency and throughput.
Postgres + pgvector: Traditional SQL database extended with vector search; great for small–medium workloads.
Side‑by‑side comparison
1. Deployment & Ops
Pinecone: Fully managed; zero ops. Best for teams that don’t want infrastructure overhead. [tensorblue.com]
Weaviate: Self‑host or managed cloud; flexible.
ChromaDB: Local-first; simple to run but not ideal for large distributed clusters.
Milvus: Requires Kubernetes‑style ops when self‑hosted; managed option via Zilliz Cloud.
Qdrant: Easy to self‑host; also has managed cloud.
Postgres/pgvector: Easiest if you already use Postgres; no new infra.
2. Performance & Scale
Milvus: Best for massive scale (billions of vectors). [tensorblue.com]
Qdrant: Excellent low‑latency performance due to Rust engine.
Pinecone: Strong performance but can get expensive at scale.
Weaviate: Good hybrid search performance; scales well.
ChromaDB: Good for small–medium RAG; not built for huge clusters.
Postgres/pgvector: Works well up to a few million vectors; slows down beyond that.
3. Pricing
(For ~10M vectors, 1536‑dim embeddings)
Pinecone: ~$200–$400/month depending on pod type. [tensorblue.com]
Weaviate Cloud: ~$150–$300/month.
Qdrant Cloud: ~$100–$250/month; cheaper due to memory‑mapped storage.
Milvus/Zilliz Cloud: ~$150–$350/month.
ChromaDB: Free self‑hosted; no managed tier.
Postgres/pgvector: Cost = your Postgres hosting; often cheapest.
4. Features
Hybrid search (vector + keyword) → Weaviate excels.
Multimodal (text, image, audio) → Weaviate and Milvus.
Metadata filtering → All support it, but Pinecone/Weaviate/Qdrant do it best.
Open‑source → Weaviate, Qdrant, Milvus, ChromaDB, pgvector.
Fully managed → Pinecone, Weaviate Cloud, Qdrant Cloud, Zilliz Cloud.

Which one should you use for RAG?
If you want the simplest experience:
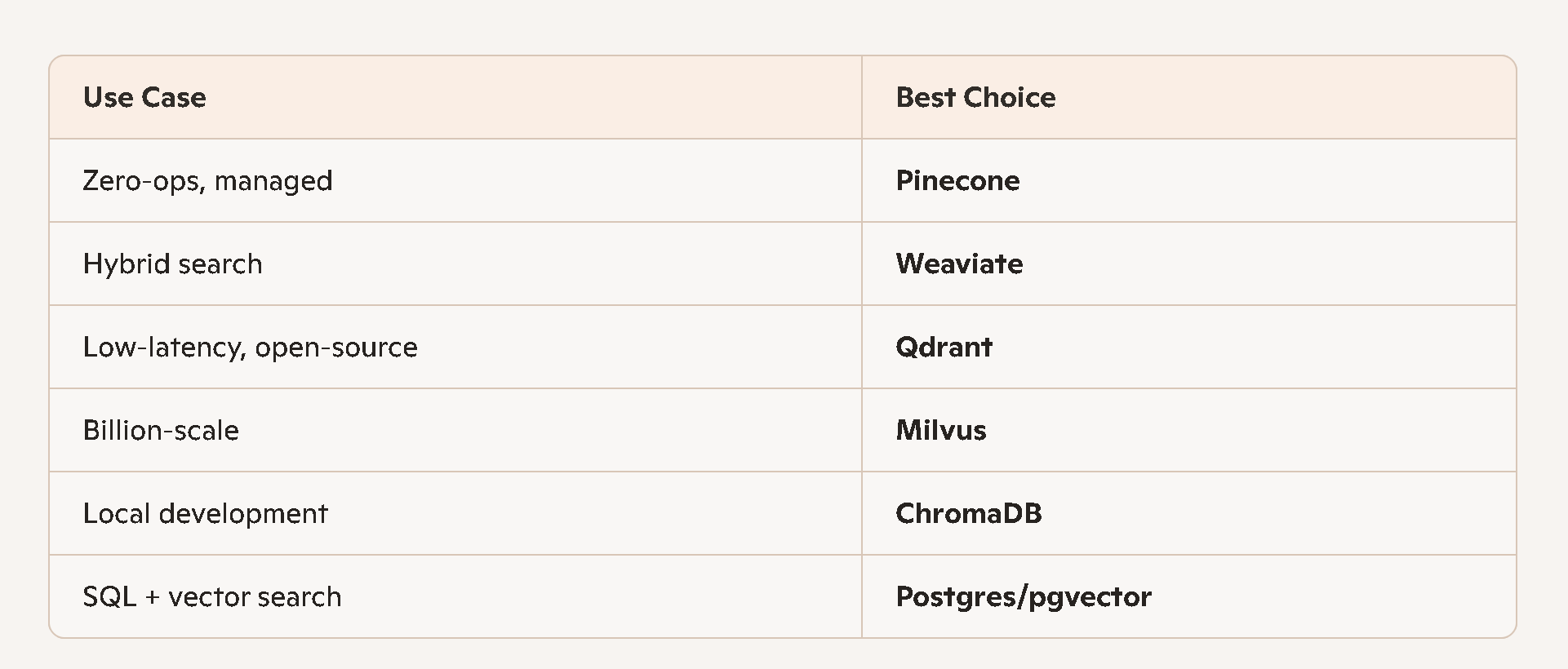
Pinecone: minimal setup, reliable, but pricier.
If you want hybrid search or multimodal:
Weaviate: strong semantic + keyword search.
If you want the fastest open‑source engine:
Qdrant: great latency and throughput.
If you need billion‑scale:
Milvus: built for massive datasets.
If you want local, simple, developer‑friendly:
ChromaDB: perfect for prototypes and small RAG apps.
If you already use Postgres:
pgvector: easiest integration; good up to mid‑scale.
🧭 Quick recommendation table
If you tell me your scale, budget, and deployment preference, I can recommend the best one for your RAG pipeline.